

界面新闻记者 | 宋佳楠
界面新闻获悉,1月26日晚,阿里端庄推出千问系列旗舰推理模子Qwen3-Max-Thinking。笔据阿里公布的数据,该模子在19项泰斗基准测试中的发达忘形OpenAI的GPT-5.2-Thinking、谷歌的Gemini 3 Pro等外洋顶尖模子,鲜艳着国产大模子在高阶推理畛域终了伏击冲破。
该模子总参数目超万亿,预考验数据量达36T Tokens,经大限度强化学习打磨而成。相较于前代模子,其中枢鼎新辘集在两方面。
一是自适宜器具调用才调,可按需调用搜索引擎和代码评释器,现已上线Qwen Chat。与早期需要用户手动选拔器具的依次不同,Qwen3-Max-Thinking能在对话中自主选拔并调用其内置的搜索、追忆和代码评释器功能。这种才调让模子能像专科东谈主士同样自主判断是否调用搜索、追忆或代码评释器,比如解答及时计策问题时自动检索最新信息,处理工程计较时运转代码器具考证成果,无需用户非凡教唆即可镌汰“幻觉”风险。
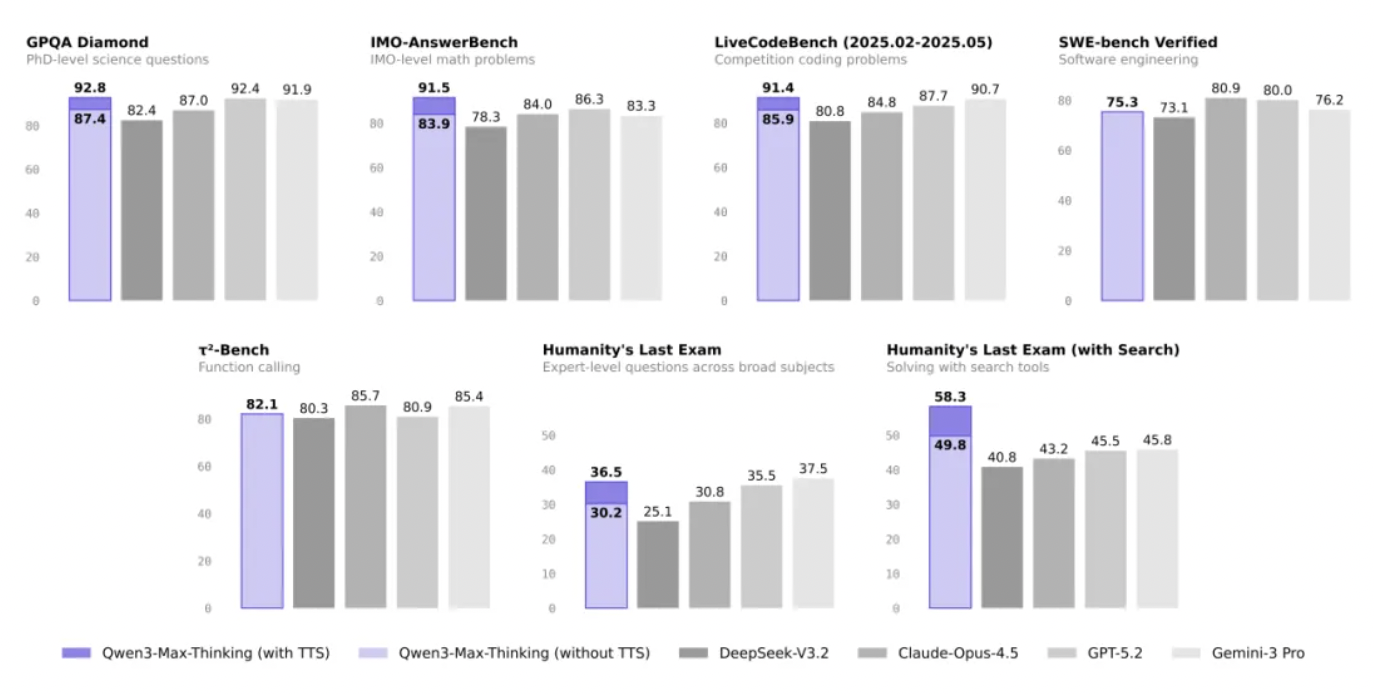 Qwen3-Max-Thinking相关测试数据 图片开头:千问
Qwen3-Max-Thinking相关测试数据 图片开头:千问
另一个是测试时扩张本事(Test-Time Scaling),指在推理阶段分拨非凡计较资源以栽种模子性能的本事。据称显赫栽种推感性能,在要津推理基准上越过Gemini 3 Pro。
一般AI碰到穷困,会同期想好多想路,好多是叠加的,白白耗算力。该本事则通过“劝诫提真金不怕火”式反想,一分彩app官方下载幸免传统模子并行推理的冗余计较,在换取算力下聚焦未科罚难点,使GPQA科学学问测试得分从90.3栽种至92.8,LiveCodeBench编程测试从88.0升至91.4。
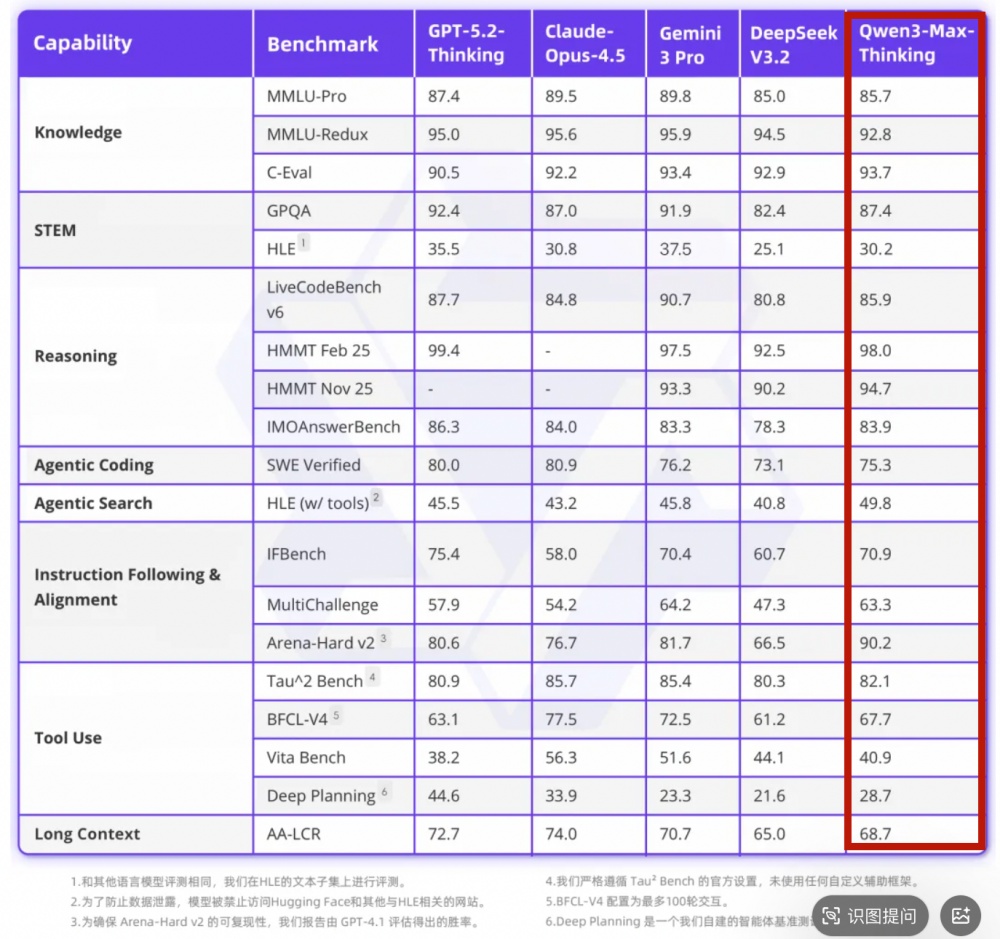 针对Qwen3-Max-Thinking的更多性能评估 图片开头:千问
针对Qwen3-Max-Thinking的更多性能评估 图片开头:千问
在性能比拼中,该模子在被称为“东谈主类临了的测试”的HLE器具调用基准中,以58.3分远超GPT-5.2-Thinking的45.5分和Gemini 3 Pro的45.8分;IMO级数学推理测试获91.5分登顶,预览版更曾拿下AIME 25与HMMT 25双满分。
现在,平方用户可通过千问PC端、网页端免费体验,企业则能通过阿里云百真金不怕火得回API做事。
1月21日,大众最大AI开源社区Hugging Face最新数据清晰,阿里千问繁衍模子数冲破20万个,成为大众首个达成此野心的开源大模子;同期,千问系列模子下载量冲破10亿次,平均每天被下载110万次,已透顶越过好意思国Llama,稳居开源大模子大众第一。
{jz:field.toptypename/}阿里CEO吴泳铭昨年曾暗示,公司正在积极鼓吹三年3800亿的AI基础形式诞生筹谋,并将会执续追加更大的干与。这一干与限度与谷歌、Meta和亚马逊等好意思股科技巨头的AI本钱开支处于统一量级。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
职守剪辑:宋雅芳

 备案号:
备案号: 